

Tukar dokumen teks ke matriks TF-IDF dengan TFIDFVectorizer
Apr 18, 2025 am 10:26 AM
Artikel ini menerangkan teknik frekuensi frekuensi-inverse frekuensi (TF-IDF), alat penting dalam pemprosesan bahasa semulajadi (NLP) untuk menganalisis data teks. TF-IDF melampaui batasan pendekatan asas beg-kata-kata dengan istilah berat berdasarkan kekerapannya dalam dokumen dan jarang mereka merentasi koleksi dokumen. Ini peningkatan berat badan meningkatkan klasifikasi teks dan meningkatkan keupayaan analisis model pembelajaran mesin. Kami akan menunjukkan cara membina model TF-IDF dari awal dalam Python dan melakukan pengiraan berangka.
Jadual Kandungan
- Syarat Utama dalam TF-IDF
- Kekerapan jangka panjang (TF) dijelaskan
- Frekuensi Dokumen (DF) dijelaskan
- Frekuensi Dokumen Songsang (IDF) dijelaskan
- Memahami TF-IDF
- Pengiraan TF-IDF berangka
- Langkah 1: Mengira kekerapan jangka panjang (TF)
- Langkah 2: Mengira Frekuensi Dokumen Songsang (IDF)
- Langkah 3: Mengira TF-IDF
- Pelaksanaan Python menggunakan dataset terbina dalam
- Langkah 1: Memasang perpustakaan yang diperlukan
- Langkah 2: Mengimport perpustakaan
- Langkah 3: Memuatkan dataset
- Langkah 4: Memulakan
TfidfVectorizer - Langkah 5: Memasang dan mengubah dokumen
- Langkah 6: Memeriksa Matriks TF-IDF
- Kesimpulan
- Soalan yang sering ditanya
Syarat Utama dalam TF-IDF
Sebelum meneruskan, mari kita tentukan istilah utama:
- t : istilah (perkataan individu)
- D : Dokumen (satu set perkataan)
- N : Jumlah dokumen di korpus
- Corpus : Koleksi keseluruhan dokumen
Kekerapan jangka panjang (TF) dijelaskan
Kekerapan jangka panjang (TF) mengukur seberapa kerap istilah muncul dalam dokumen tertentu. TF yang lebih tinggi menunjukkan kepentingan yang lebih besar dalam dokumen itu. Formula adalah:
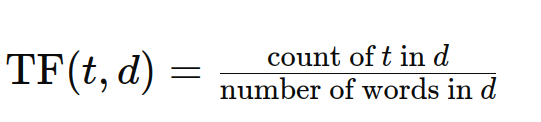
Frekuensi Dokumen (DF) dijelaskan
Kekerapan dokumen (df) mengukur bilangan dokumen dalam korpus yang mengandungi istilah tertentu. Tidak seperti TF, ia mengira kehadiran istilah, bukan kejadiannya. Formula adalah:
Df (t) = bilangan dokumen yang mengandungi istilah t
Frekuensi Dokumen Songsang (IDF) dijelaskan
Kekerapan dokumen songsang (IDF) menilai maklumat mengenai perkataan. Walaupun TF merawat semua istilah sama, kata -kata bawah tanah IDF (seperti kata -kata berhenti) dan istilah yang lebih jarang. Formula adalah:
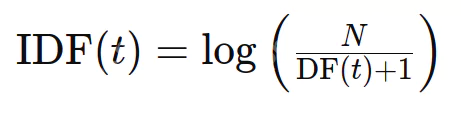
di mana n ialah jumlah dokumen dan df (t) adalah bilangan dokumen yang mengandungi istilah t.
Memahami TF-IDF
TF-IDF menggabungkan kekerapan jangka panjang dan kekerapan dokumen songsang untuk menentukan kepentingan istilah dalam dokumen berbanding dengan keseluruhan korpus. Formula adalah:
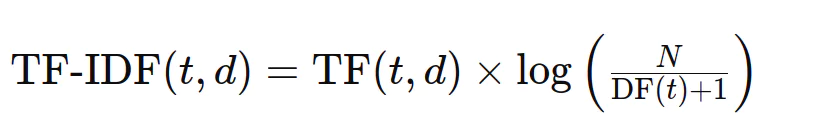
Pengiraan TF-IDF berangka
Mari kita gambarkan pengiraan TF-IDF berangka dengan dokumen contoh:
Dokumen:
- "Langit berwarna biru."
- "Matahari cerah hari ini."
- "Matahari di langit cerah."
- "Kita dapat melihat matahari bersinar, matahari yang cerah."
Berikutan langkah-langkah yang digariskan dalam teks asal, kami mengira TF, IDF, dan kemudian TF-IDF untuk setiap istilah dalam setiap dokumen. (Pengiraan terperinci ditinggalkan di sini untuk keringkasan, tetapi mereka mencerminkan contoh asal.)
Pelaksanaan Python menggunakan dataset terbina dalam
Bahagian ini menunjukkan pengiraan TF-IDF menggunakan TfidfVectorizer Scikit-Learn dan dataset 20 kumpulan berita.
Langkah 1: Memasang perpustakaan yang diperlukan
PIP Pasang SCIKIT-Learn
Langkah 2: Mengimport perpustakaan
Import Pandas sebagai PD dari sklearn.datasets import fetch_20newsgroups dari sklearn.feature_extraction.text import tfidfvectorizer
Langkah 3: Memuatkan dataset
kumpulan berita = fetch_20NewSgroups (subset = 'kereta api')
Langkah 4: Memulakan TfidfVectorizer
vectorizer = tfidfvectorizer (stop_words = 'english', max_features = 1000)
Langkah 5: Memasang dan mengubah dokumen
tfidf_matrix = vectorizer.fit_transform (newsgroups.data)
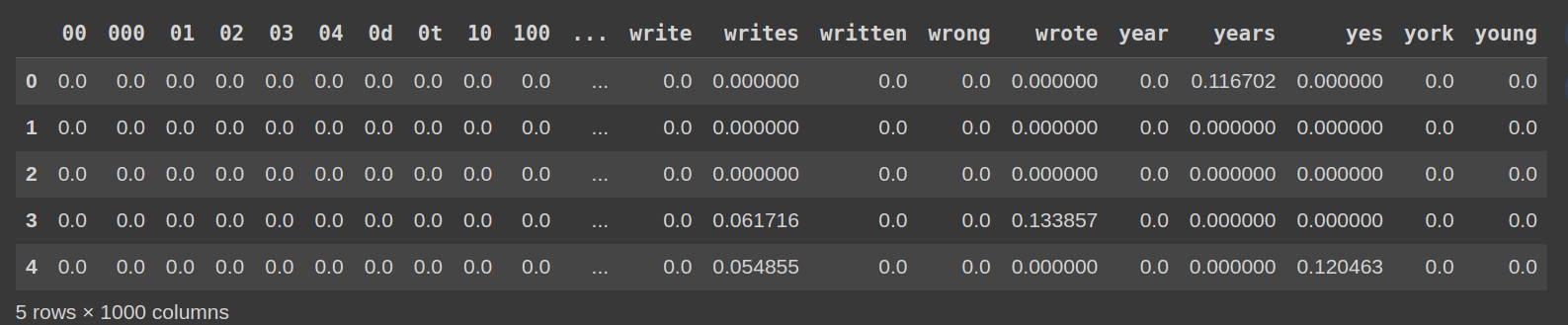
Langkah 6: Memeriksa Matriks TF-IDF
df_tfidf = pd.dataFrame (tfidf_matrix.toarray (), lajur = vectorizer.get_feature_names_out ()) df_tfidf.head ()
Kesimpulan
Menggunakan 20 kumpulan kumpulan berita dan TfidfVectorizer , kami dengan cekap mengubah dokumen teks ke dalam matriks TF-IDF. Matriks ini mewakili kepentingan setiap istilah, membolehkan pelbagai tugas NLP seperti klasifikasi teks dan kluster. TfidfVectorizer Scikit-Learn memudahkan proses ini dengan ketara.
Soalan yang sering ditanya
Seksyen Soalan Lazim tetap tidak berubah, menangani sifat logaritma IDF, skalabilitas kepada dataset yang besar, batasan TF-IDF (mengabaikan perintah dan konteks perkataan), dan aplikasi umum (enjin carian, klasifikasi teks, kluster, ringkasan).
Atas ialah kandungan terperinci Tukar dokumen teks ke matriks TF-IDF dengan TFIDFVectorizer. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undress AI Tool
Gambar buka pakaian secara percuma

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Alternatif Notebooklm Top 7 Top
Jun 17, 2025 pm 04:32 PM
Alternatif Notebooklm Top 7 Top
Jun 17, 2025 pm 04:32 PM
NotebookLM Google adalah alat pengambilan nota AI pintar yang dikuasakan oleh Gemini 2.5, yang cemerlang dalam meringkaskan dokumen. Walau bagaimanapun, ia masih mempunyai batasan penggunaan alat, seperti topi sumber, pergantungan awan, dan ciri "Discover" baru -baru ini
 Sam Altman mengatakan AI sudah melewati ufuk acara tetapi tidak ada kebimbangan kerana Agi dan ASI akan menjadi singulariti lembut
Jun 12, 2025 am 11:26 AM
Sam Altman mengatakan AI sudah melewati ufuk acara tetapi tidak ada kebimbangan kerana Agi dan ASI akan menjadi singulariti lembut
Jun 12, 2025 am 11:26 AM
Mari kita menyelam ini. Sekeping ini menganalisis perkembangan terobosan di AI adalah sebahagian daripada liputan saya yang berterusan untuk Forbes mengenai landskap kecerdasan buatan yang berkembang, termasuk membongkar dan menjelaskan kemajuan dan kerumitan utama AI utama
 Hollywood menuntut firma AI kerana menyalin watak tanpa lesen
Jun 14, 2025 am 11:16 AM
Hollywood menuntut firma AI kerana menyalin watak tanpa lesen
Jun 14, 2025 am 11:16 AM
Tetapi apa yang dipertaruhkan di sini bukan sekadar ganti rugi retroaktif atau pembayaran balik royalti. Menurut Yelena Ambartsumian, tadbir urus AI dan peguam IP dan pengasas Ambart Law PLLC, kebimbangan sebenar adalah berpandangan ke hadapan. "Saya fikir Disney dan Universal's MA
 Alphafold 3 memanjangkan kapasiti pemodelan kepada sasaran lebih banyak biologi
Jun 11, 2025 am 11:31 AM
Alphafold 3 memanjangkan kapasiti pemodelan kepada sasaran lebih banyak biologi
Jun 11, 2025 am 11:31 AM
Melihat kemas kini dalam versi terkini, anda akan melihat bahawa Alphafold 3 memperluaskan keupayaan pemodelannya ke pelbagai struktur molekul yang lebih luas, seperti ligan (ion atau molekul dengan sifat mengikat tertentu), ion lain, dan apa yang refe
 Penyemak imbas Dia dibebaskan - dengan AI yang tahu anda suka rakan
Jun 12, 2025 am 11:23 AM
Penyemak imbas Dia dibebaskan - dengan AI yang tahu anda suka rakan
Jun 12, 2025 am 11:23 AM
DIA adalah pengganti kepada arka penyemak imbas yang terdahulu. Pelayar telah menggantung pembangunan arka dan memberi tumpuan kepada DIA. Penyemak imbas itu dikeluarkan dalam beta pada hari Rabu dan dibuka kepada semua ahli ARC, sementara pengguna lain dikehendaki berada di senarai menunggu. Walaupun ARC telah menggunakan kecerdasan buatan banyak -seperti mengintegrasikan ciri -ciri seperti coretan web dan pratonton pautan -DIA dikenali sebagai "pelayar AI" yang memfokuskan hampir sepenuhnya pada AI generatif. Ciri-ciri Pelayar Dia yang paling menarik di Dia mempunyai persamaan dengan ciri penarikan balik kontroversial di Windows 11. Pelayar akan mengingati aktiviti terdahulu anda supaya anda boleh meminta AI
 Apa yang kelihatan seperti AI di syarikat anda?
Jun 14, 2025 am 11:24 AM
Apa yang kelihatan seperti AI di syarikat anda?
Jun 14, 2025 am 11:24 AM
Menggunakan AI tidak sama dengan menggunakannya dengan baik. Ramai pengasas telah menemui ini melalui pengalaman. Apa yang bermula sebagai percubaan menjimatkan masa sering mewujudkan lebih banyak kerja. Pasukan akhirnya menghabiskan berjam-jam menyemak semula kandungan yang dihasilkan AI atau mengesahkan output
 Prototaip: Saham Saham Syarikat Voyager Soars di IPO
Jun 14, 2025 am 11:14 AM
Prototaip: Saham Saham Syarikat Voyager Soars di IPO
Jun 14, 2025 am 11:14 AM
Space Company Voyager Technologies menaikkan hampir $ 383 juta semasa IPOnya pada hari Rabu, dengan saham yang ditawarkan pada $ 31. Firma itu menyediakan pelbagai perkhidmatan yang berkaitan dengan ruang kepada pelanggan dan pelanggan komersial, termasuk aktiviti di dalam
 Dari Adopsi ke Kelebihan: 10 Trend Membentuk LLMS Enterprise pada tahun 2025
Jun 20, 2025 am 11:13 AM
Dari Adopsi ke Kelebihan: 10 Trend Membentuk LLMS Enterprise pada tahun 2025
Jun 20, 2025 am 11:13 AM
Berikut adalah sepuluh trend yang menarik yang membentuk semula landskap AI perusahaan. Komitmen kewangan untuk llmsorganizations secara signifikan meningkatkan pelaburan mereka di LLM, dengan 72% menjangkakan perbelanjaan mereka meningkat tahun ini. Pada masa ini, hampir 40% a
